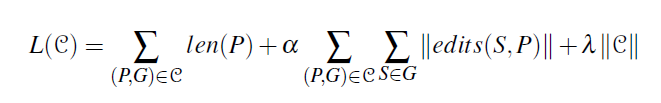论文笔记Sequence Synopsis-vast17
Sequence Synopsis: Optimize Visual Summary of Temporal Event Data
暑假夏令营复现的论文,看的时候做的笔记。
前置知识
-
MDL principle
最小描述长度,需要保存的数据长度(比特数) 等于这些实例数据进行编码压缩后的长度加上保存模型所需的数据长度,将该数据长度称为总描述长度。
-
event sequence analysis
数据是多个时间戳或有序事件的系列。事件序列分析是指在进行系统故障和安全分析时,从各种假设始发事件开始,根据设计,按照逻辑顺序分析其系统部件和运行人员可能的动作及其后果,直至最终安全状态或事故状态的一系列事件。
内容
-
background
- 领域:事件序列的可视化
- 那么什么是事件序列?可以理解为有时序性的事件的串。比如一个事件可以理解为谁在什么时间做了什么事情,事件序列的数据就是把事件按照时间等顺序排列下来。
- 比如车辆的行车记录,每个事件发生了什么动作或者故障,就可以记录下来,分析这个数据,typical fault development paths can be identified,辅助进行车辆改造。
- 再比如user interaction logs in software applications,分析这个数据,usability issues and user behavior patterns~~
can be identified to inform better designs of the interface.
- 那为了更好的分析数据,自然就有了可视化事件序列的需求。
-
motivation
- a variety of visualization techniques have been proposed in the past years - SPM / 序列聚类 存在什么问题
- 现实世界的data noisy & high dimension
- 直观,简单而全面:it still remains a challenging task to create intuitive, simple, yet comprehensive overviews for real-world event sequence data.
-
related work
- 以前为什么不能解决 intuitive, simple, yet comprehensive
- Sankey diagram:cannot handle noisy data with high event cardinality 放一个图上去,这基数大了显然不行,不管是维度还是长度
- SPM algorithms:提供一堆statistically relevant patterns between data examples where the values are delivered in a sequence,但会有很多冗余,要分析人员自己筛选
- 序列聚类:可以给overview of data,但是序列聚类的算法难以解释(这里有疑问,为什么难以解释 - 基于距离的度量比基于结构的度量好解释,线性的关系比非线性的好解释,低维比高维好解释,序列聚类并不符合【好解释】这一点,具体要去看一下算法)
- 以前为什么不能解决 intuitive, simple, yet comprehensive
-
目标:construct a coarse-level overview of the data with a good balance between the simplicity of the visual representation and its information content.
-
method
-
基本思想:
- 使用算法找到事件序列类似的部分
- 可以理解为特征序列,举个例子,每个车辆出故障前后的事件可能是相似的,可以帮助定位车辆出故障的原因。
- 构建可视分析系统,帮助探索数据
- 使用算法找到事件序列类似的部分
-
方法:
-
简单概括:
-
two-part representation,a set of sequential patterns and a set of corrections. 每个sequence maps to a pattern,correction可以通过pattern恢复原始数据。
-
可视化,通过pattern构建数据的overview,每个pattern代表了一组序列,事件用矩形表示,从左到右排列。高度表示含有此事件的序列数量,三角形大小表示the number of insertions
-

-
那怎么搞pattern,简明不损失信息:MDL
- MDL在model复杂度和model对原始数据的描述长度权衡
- 本质上与我们目标一致:1)pattern是模型,2)correction和pattern结合来描述原始数据。能做到序列聚类&模式提取,容忍噪声。
-
MDL:最小描述长度,需要保存的数据长度(比特数) 等于这些实例数据进行编码压缩后的长度加上保存模型所需的数据长度,将该数据长度称为总描述长度。
-
目标:找这个最小值

解释一下:
- pattern长度
- edits(S,P)从S到P的set of edits, an edit can be fully specified by the position and the event involved and its description length can be roughly treated as a constant,所以算的是个数
- 最后一项控制pattern数量
-
算法:
-
MinDL:基本迭代
我放出来的三个框:初始化,长度有变短就插入集合,每次取出长度变化最大的做merge
-
加权LSH加速,搜索时跳过长得很不像的sequence/pattern
-
设置一个阈值th,相似度大于阈值,hash value大概率一样
-
weighted LSH可以快速识别相似的sequence/pattern,不管event确切顺序
-
为了不漏掉内容,th逐渐减小
-
-
-
-
可视系统细节:
从左到右,Data filter,Summary view,Detailed view

summary view展示sequential patterns,点击pattern会在右边显示所有对应的sequence,双击三角形看下一级的detail,双击矩形会对某个事件在Summary view和Detailed view做对齐**(这个功能重点强调)**,比如对error双击,就能看到在此之前主要是做了什么操作,随后会导致error。
Event filter展示了所有event的相关性,focus在中间的事件,距离表示了相关性的大小。点击某一个事件可以切换focus,也可以刷选一个subset of events,summary view会相应的刷新数据。
-
-
-
evaluation
- 怎么验证可行:experts,汽车应用场景
- usage scenario * 2