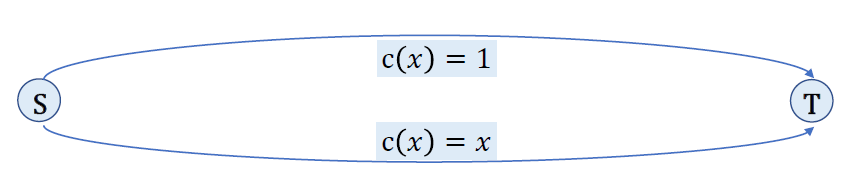计算机视觉复习
引言
- 格式塔法则Gestalt law
- 接近原则proximity:接近、临近的物品认作一个整体
- 相似原则similarity:相似的物体感知成同一组的部分
- 共同命运原则common fate:将以相同的速度和(或)方向运动的物体感知成一个组
- 对称原则symmetry:互相对称的元素容易被感知为统一的组
- 连续性原则contimuity:若图形的某些部分可以被看作连接在一起的,则这些部分很可能被认为是一个整体
- 封闭/闭合原则closure:把不完整的没有闭合的个体看成是一个整体的形状
- Marr视觉表示框架的三个阶段
- 第一阶段 (Primal Sketch):将输入的原始图像进行处理,抽取图像中诸如角点、边缘、纹理、线条、边界等基本特征, 这些特征的集合称为基元图;
- 第二阶段 (2.5D Sketch):指在以观测者为中心的坐标系中, 由输入图像和基元图恢复场景可见部分的深度、法线方向、 轮廓等,这些信息包含了深度信息,但不是真正的物体三维表示,因此被称为二维半图;
- 第三阶段 (3D Model):在以物体为中心的坐标系中,由输入图像、基元图、二维半图来恢复、表示和识别三维物体。
二值图像
-
几何特性(举例)
- 面积(零阶矩),区域中心(一阶矩)
- 方向(最小二乘法)
- 伸长率,密集度,形态比
- 欧拉数 (亏格数, genus) = 连通分量数减去洞数
-
投影计算:
- 原理:给定直线,用垂直该直线的等间距线把图像分隔成若干条,计算每一条内像素值为1的数量
- 垂直水平很简单
- 对角线做仿射变换:对于的图像,对每一个做计算。其中,。
-
连通区域:
-
连通分量标记算法(贯序)(二重循环+并查集)
- 从左到右,从上到下扫描图像
- 如果像素点值为1,则分四种情况:
- 如果上面点和左面点有且仅有一个标记,则复制这一标记
- 如果两点有相同标记,则复制这一标记
- 如果两点有不同标记,则复制上点的标记且将这两个标记输入等价表中作为等价标记
- 否则给这一像素点分配一个新的标记并将这一标记输入等价表
- 如果需要考虑更多的点,则返回2
- 在等价表的每一等价集中找到最低的标记
- 扫描图像,用等价表中的最低标记取代每一标记
-
区域边界跟踪算法:针对某一个连通区域/分量算轮廓
-
从左到右、从上到下找到左上角的起点,初始化为,初始化是它左侧的点。容易知道。
-
从开始围绕逆时针旋转,标号到,找第一个.
置(保证了),重复操作直到回到起点。
-
-
边缘(特征)
-
模板卷积
- 计算:给一个图像,一个模板,计算卷积结果。
- 边缘有四种原因(四种最主要的不连续)
- 表面法向量的不连续
- 深度的不连续
- 表面颜色的不连续
- 光照的不连续
-
边缘检测基本思想:函数导数反映图像灰度变化的显著程度,能够检测灰度不连续的地方。一阶导数的局部极大值,或二阶导数的过零点。
-
基于一阶的边缘检测:
- 梯度:二维函数的一阶导数
- 梯度幅值:
- 梯度方向:
- Roberts交叉算子:幅值近似而来,为右下点减自己,为下点减右点。(两个对角线方向)2*2
- Sobel算子:为左边,中间全0;为上面,中间全0。3*3
- Prewitt算子:运算较快,左边都是,上面都是1。3*3
-
基于二阶的边缘检测:
-
拉普拉斯算子:二阶导数的二维等效式,用差分近似微分
- 中间-4,上下左右1,角点0
- 邻域中心点具有更大权值:中间-20,上下左右4,角点1
-
LoG算子
- 平滑滤波器是高斯滤波器。
- 采用拉普拉斯算子计算二阶导数。
- 边缘检测判据是二阶导数零交叉点并对应一阶导数的较大峰值。
- 使用线性内插方法在子像素分辨率水平上估计边缘的位置。
- 先做卷积再求二阶导 和 先对高斯滤波求二阶导再卷积 等价。
- 算子5*5:中间16 ,上下左右-2,再一圈-1
-
为什么要加高斯 from canny边缘检测,不知道对不对
update:二阶导数对噪声比较敏感,加高斯可以起到平滑的作用,能够减少噪声的影响。
-
-
Canny边缘检测:具体掌握,每个步骤怎么做的,为什么,能说出其中两个阈值的含义。
-
用高斯滤波器平滑图像
-
用一阶偏导有限差分计算梯度幅值和方向
-
对梯度幅值进行非极大值抑制(NMS)
- 先将所有梯度角离散为圆周的八个扇区之一(方向角离散化)以便用3*3的窗口做抑制运算,然后去掉不比梯度线方向上的两个相邻点幅值大的点(抑制)
-
-
为什么:可以进一步消除非边缘的噪点,更重要的是可以细化边缘,将模糊的边界变得清晰
-
用双阈值算法检测和连接边缘,得到高阈值图和低阈值图,连接高阈值图,出现断点时在低阈值边缘图的8邻点域搜索。
- 高阈值:必然是边缘
- 低阈值:必须和高阈值连通才算边缘
- 解释:阈值太高丢失轮廓,太低假边缘,结合起来用是更有效的阈值方案。
局部特征 Local Feature
-
Harris角点检测
-
基本思想:给定包围一个点的窗口,在任何方向上移动窗口,强度都会发生较大变化,即为角点
-
公式推导:Harris算法是利用窗口内图像的灰度自相关性进行的,设定一个窗口并在图像中移动,计算移动前与移动后窗口所在的区域图像的自相关系数

-
相当于一个椭圆的函数。
:其-1/2次方是变化最快方向
:其-1/2次方是变化最慢方向其中一个特征值显著更大:edge
两个特征值都很大:corner。 increases in all directions。
其他:flat。说明在所有方向都变化不大。
-
:正方向很大为corner,负方向很大为edge,绝对值小的地方为flat
-
算法:设定threshold,找R大于threshold的点,取局部最大的点。
-
**Harris角点有旋转不变性,但没有尺度不变性:**旋转不变性是因为我们取的是局部最大。尺度放大以后,一个原来的角点可能会被检测成edge。
设计一个尺度不变函数:
- 在多尺度检测关键点
- 然后找上下不同尺度的局部最大值
- 消除低于阈值的点
-
灰度仿射不变性:部分不变;平移、偏置不变性。不影响前几个特征点且大小顺序不变。可以做均衡化?(拉伸大小或者加偏移量)
-
-
SIFT描述子的计算
-
计算步骤:
- 对特征点(检测图像)做16*16的square窗口(将16*16分成16个4*4的窗口)
- 计算窗口中每个像素的边的方向(梯度角减去90°)
- 丢掉方向能量小的边(使用阈值)
- 用直方图描述结果(将每个小窗口中的所有的方向离散成8个方向,一共16*8=128个)
-
最重要的信息:梯度。为什么要用梯度?
因为梯度信息可以表示边缘信息,并且在光照变化时有抵抗能力
-
如何实现旋转不变:
因为我们找的是对应位置的参考方向而非绝对方向
(在去掉weak的方向之后,有一步是选择主方向,然后整个旋转过去,再求直方图,所以旋转不变,都对准了最大的方向)
-
-
尺度不变的原理:
决定窗口大小的是随尺度变化并且是单峰的函数,能够找到极值。
因为在使用高斯模糊的不同尺度(如图像金字塔)处重新采样图像,仅当在两个尺度之间观察到最大值时才将梯度存储为描述符




曲线
- Hough变换
- Hough变换是基于投票原理的参数估计方法,是一种重要的形状检测技术,可以用来检测直线、圆等形状。
- 基本思想:图像中的每一点对参数组合进行表决,赢得多数票的参数组合为胜者(结果)
- 直线原理:
- 原图的一个点 上会经过很多 的直线。我们写成 的形式,做 的映射。
- 这样,原图的每一个点就转换成了参数空间中的直线。
- 避免垂直直线所带来的问题,通常采用极坐标表示: 空间到 空间的变换。
- 在参数空间开一个累加器。对于原图的每个点,把参数空间对应直线经过的点累加器都加一。最终我们再把参数空间里值最大的累加器点变换回原图,就可以表征原图最有可能的直线了。
- 直线步骤:
- 适当地离散化参数空间
- 假定参数空间每一个单元都是一个累加器,把累加器初始化为0
- 对图像空间的每一点,在其所满足的参数方程对应的累加器上加1
- 累加器阵列最大值对应模型的参数
- 圆弧原理:
- 一个圆弧有 三个参数。
- 由 得变换规则 :(参数空间是 )
- 对于原图的每个点计算梯度角 ,并在对应参数空间维护累加器。做完后我们就得到了最有可能的圆心坐标。很容易反求出 。
- 圆弧步骤:
- 量化关于a,b的参数空间到合适精度
- 初始化所有累加器为0
- 计算图像空间中边缘点的梯度幅度和角度
- 若边缘点参数坐标满足则该参数坐标对应的累加器加1
- 拥有最大值的累加器所在的坐标即为图像空间中的圆心之所在
- 得到圆心坐标之后,我们可以很容易反求r
- 离散化:
- 精度高:噪声太多。计算机只能对离散的情况投票,例如参数是2.4,精度划分到2.44444的话,就会导致投票分散噪声过多,不利于检测。
- 精度低:离散化过于不细致,例如参数是8,精度只有5的话,就会算到10,与真正的形状差距过大。
主元分析与人脸识别
-
主元分析(PCA)
-
基本思想:是一种简化数据的技术,选择一个新的坐标系统进行线性降维,第一轴是数据集的投影的方差最大的方向,第二轴是数据集投影的方差第二大方向。能够以降维的方式提取特征。
-
主要作用:降维和去噪
-
什么样的数据比较有效?高斯分布,多维高斯,多元高斯分布。这里的含义:重构的含义,重构误差比较小。
-
函数推导:
- 数据在 维空间
- 我们想要找一些投影方向 ,使得 且投影值 的方差尽量大。求投影方向
- 同时限制 ,即每个新方向都与原方向无关。
-
求解:
- 令 ,则
- 我们要最大化 ,等式约束下的最大化问题
- 套用 Lagrange 乘子法后,转为最大化 .
- 求微分,得 ,即应该取 的特征值。
-
结论:为了最大化,求 的前 大特征值,用最大特征值对应的特征向量,即为变换方式。
-
选取多少个特征向量构建子空间
-
-
Eigenface
- 是什么:所有人脸图像展开后构成的大矩阵的协方差矩阵的特征向量
- 人脸识别方法基本步骤
- 获得人脸图像训练集
- 对人脸图像归一化处理
- PCA计算获取一组特征向量
- 将每幅图像投影到特征向量的空间中,得到新的空间的坐标
- 对输入的待测试图像,归一化后投影到特征人脸空间中,然后用某种距离度量来描述两幅人脸图像的相似性,如欧氏距离
- 把重构用于人脸检测的原理
- 人脸投影到特征人脸空间中,保留了主要特征的信息,所以可以恢复人脸本来的样子


图像频域与图像分解
这里主要是理解,不需要推导计算。感性理解图像频域到底是怎么回事。
-
图像傅里叶变换
- 基本含义:傅里叶变换讲的是任何信号(如图像信号)都可以表示成一系列正弦信号的叠加,在图像领域就是将图像brightness variation 作为正弦变量。傅里叶变化储存每一个频率的magnitude和phase信息,前者代表这个频率上有多少信号,后者间接可代表空间信息。
- 低频成分高频成分:图像的高频部分是像素值变化剧烈的地方,如图像的边缘和轮廓。低频部分是变化不剧烈的地方,对应大的色块。我们从近处看图像看到的是高频信息,而远处看到的是低频信息
-
图像分解
-
金字塔的方式分解,不需要公式。
-
-
怎么理解每一层是带通滤波:拉普拉斯金字塔是通过源图像减去先缩小再放大的一系列图像构成的。下采样的时候丢失了高频信息,而相邻金字塔相减的时候丢失了低频信息,因此只有中间频段的信息保留了下来
-


图像拼接
- RANSAC算法:随机抽样一致算法
- 解决什么问题?减少outliner的影响。
- outliner:如果一个outliner被选出来计算current fit,那resulting line对其他point不会有什么支持。
- 采用迭代的方式从一组包含outliers的数据中估算数学模型的参数。
- 核心思想是随机性和假设性,随机性是根据正确数据出现的概率去随机选取抽样数据,假设性是假设选取出的抽样数据都是正确数据。
- 优点:是大范围模型匹配问题的一个普遍意义上的方法,且运用简单,计算快。
- 缺点:只能计算outliers不多的情况(投票机制可以解决outliers高的情况)
- 步骤,迭代循环的步骤:
- 随机选择一些点作为样本
- 计算选出的样本应该使用的变换矩阵
- 把刚才没有选中的点代入建立的模型,判断有多少点符合,误差是否小于阈值
- 比较匹配数量是否为当前最优解,如果是,则更新当前最优集,并更新迭代次数
- 重复多次,如果迭代次数大于K(k由最优的inliers的点集计算得到),则退出,否则迭代次数+1
- outliner:不一定是噪声,可能不是这个模型的data,造成比较坏的影响的点。比例给定的情况下,计算成功的概率?
- 解决什么问题?减少outliner的影响。
- 图像拼接:自动拼接的基本步骤
- 检测关键点
- 计算SIFT描述子
- 匹配SIFT描述子
- 计算变换矩阵,进行仿射变换
- RANSAC
- 图像混合(边缘平滑过渡)
物体识别
-
四类任务:
- 图片分类
- 检测和定位物体/图片分割
- 估计语义和几何属性
- 对人类活动和事件进行分类
-
挑战因素:视角变换,光线变化,尺度变化,物体形变,物体遮挡,背景凌乱,内部类别多样
-
基于BoW的物体分类:bag of words,借鉴文本处理
- BoW的意思:图像中的单词被定义为一个图像块的特征向量,图像的Bow模型即图像中所有图像块的特征向量得到的直方图
- 基本步骤:
- 特征提取和表示(grid),每个特征为一个质点
- 通过对质点聚类建立字典(k 聚类),得到k个聚类中心,聚类中心就是词袋中的单词,所有聚类中心就是特征直方图的基
- 将图片用直方图的基表示出来,这样就可以得到关于图片的特征直方图。该直方图与单词的顺序没有关系,而是每个单词在图片中出现的频率
- 将新的图片获取质点,然后映射到直方图上进行聚类
-
基于卷积全局优化的物体分类
-
Feature Extractor: , 10 * 1024,matrix of weight vectors. :1024 * 1 image vector. :10 * 1 vector of class probabilities
-
希望概率在0到1之前,并且所有类别可能性加起来要是1。解决办法:利用Softmax函数。
-
则现在我们得到了Feature extractor和classifier:
-
我们希望我们预测的结果和实际上的是一样的(实际上的y:0001000……),即:
-
这需要我们加一个loss函数,其中是我们对正确类别的预测值。
-
取W为:
,即对所有x(原图)y(相应的分类)的W的loss求和,取一个loss最小时候的W。 -
具体loss函数的原理如图:
-
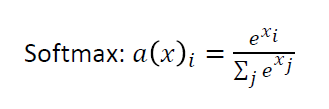

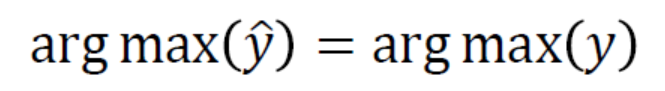
 ,即对所有x(原图)y(相应的分类)的W的loss求和,取一个loss最小时候的W。
,即对所有x(原图)y(相应的分类)的W的loss求和,取一个loss最小时候的W。
深度学习
-
基本概念,怎么理解end to end的学习:一两句话解释。
- 概念:从数据中学习层次表示。
- end to end:raw inputs to predictions. 输入是原始数据,输出是最后的预测结果。
-
-
神经网络的学习,数学本质上是求解什么,常用的基本方法(连接的权重?)
- 本质是求连接的权重。
- 复合求导,求解函数模型,实现数据的逼近和拟合;CNN
-
写出基于梯度下降法的学习框架。先做什么后做什么,怎么循环迭代。(怎么把权重求出来)
-
思想:目标是找到最好的权重,使得最小。从随机的位置开始,take tiny steps downhill and repeat。
-
w的梯度给出了提升最陡的方向。
-
w初始化一个随机值,计算梯度,下移一个较小的步长。:learning rate
-
对复杂的模型来说,求梯度很复杂。所以实际上应该有简化。
-
-
CNN
-
CNN是若干卷积层和非线性变换(如sigmod,ReLU)的序列;通过filter计算的时候,展开点乘+bias
-
卷积层:用于提取图像中的特征
-
池化层:降低数据体的空间尺寸,减少神经网络中的计算量,有效控制过拟合;同时不损失过多信息。(MAX operation most common)
-
引入这两个层是卷积神经网络和多层感知机最大的区别
-
神经元数,权重数(可以参数共享,不共享就是连接数),参数,连接数
-
height,width,depth
-
output size: ,depth不变
-
池化层也有相应的filter大小和stride,算法一样,每个地方取max就是max pooling
-
训练:用梯度下降Backpropagation算法
-
-
BP算法:
-
BP算法能学习和存储大量输入-输出模式映射关系,而无需事先揭示描述这种映射关系的数学方程
-
梯度下降需要一个下降方向,BP算法得到的就是这个方向。
BP算法中需要用到梯度下降法,用来配合反向传播;BP算法给梯度下降法提供所需要的所有参数,梯度下降法是求局部最好的权重
-






光流
(做运动估计)
-
光流解决的是什么问题
- 给定两张图像H和I,评估从H到I的像素运动,解决的是像素对应的问题
-
三个基本假设是什么,英文中文名称至少有一个会写,每个假设能用一小句话解释
- 亮度一致brightness constancy:图像在一个小区域中的measurement(如brightness)是相同的,尽管位置有变动。
- 空间一致spatial coherence:相邻的点处于空间中同一表面,具有相似的运动;Since they also project to nearby points in the image, we expect spatial coherence in image flow
- 移动小small motion:一个表面片(surface patch)在图像中的运动是随着时间逐渐改变的。
-
一个点的约束公式推导(用了两个假设)
-
亮度一致:假设
-
移动小:假设和小于一个像素
-


-
In the limit as u and v go to zero, this becomes exact
-
哪些位置光流比较可靠,解释原因(定性判断)
- 纹理复杂区域,梯度比较大且方向不同,求出来的特征值比较大
相机模型
-
定性的判断:景深/光圈/焦距/视场。含义和约束关系,怎么影响,为什么这么影响,能够自己解释。
-
**景深:**相机镜头能够取得清晰图像的成像所测定的被摄物体前后范围距离
**光圈:**镜头中,用来控制光线透过镜头,进入机身内感光面光量的装置
**焦距:**从镜片中心到底片等成像平面的距离
**视场:**摄像头能够观察到的最大范围 -
光圈对景深:较小的光圈对应较大的景深(但是较小的光圈限制了光线的进入,因此需要增加曝光)
-
焦距对视场:焦距越短,视场角越大,放大倍率越小,拍摄范围越大,拍摄画面中的人越小(景深越大?)
-
-
针孔相机模型:
投影过程:
-
相机模型有哪几个内参(不包括畸变参数);内参矩阵:
:image plane到center在x方向上的距离(in pixel),x方向以像素为单位的焦距
:image plane到center在y方向上的距离(in pixel),y方向以像素为单位的焦距
:中心点的在x方向的偏移
:中心点的在y方向的偏移
下面这张图大括号里的X和Y反了,注意
内参矩阵M:(这样q算出来是原来的Z倍,但就可以变成矩阵操作了)
即齐次坐标下的投影
好处:变成线性变换,所有的操作都被归到矩阵操作。
-
-
畸变/失真distortion
-
径向和切向畸变产生的原因
- **径向畸变:**不完美的镜头造成,比如镜头的几何性质或者光圈位置。远离透镜中心的地方比靠近中心的地方更加弯曲。radial
- 切向畸变:感光元件摆放倾斜。例如由于CMOS等感光元件摆放倾斜,没有平行于图像平面。tangential
-
径向畸变常见的有哪两种
-
枕形畸变:
桶形畸变:
-
-
-
外参有哪几个,分别代表什么含义,齐次坐标下的外参矩阵
外参用于模型空间到相机空间的变化,三个参数是平移参数,三个参数是旋转参数。
T=Cw-Ow
t = RT










-
画图展示内参、外参、畸变参数在成像各阶段中的角色(真实世界坐标到图像坐标,哪个步骤起什么作用)
-
第一步是从世界坐标系转为相机坐标系,这一步是从三维点到三维点的转换,包括R,t等参数(相机外参)
- Translation T of the optical center from the origin of world coords
- Rotation R of the image plane
-
第二步是从相机坐标系转为成像平面坐标系(像素坐标系),这一步是三维点到二维点的转换,包括f,c等参数(相机内参)
-
最后再用到畸变参数
-
-
相机定标:需要求解哪些参数,解决这个问题的基本思想(怎么求的,原理)。
- 求解哪些参数:畸变参数,内参,外参
- 基本思想:给定一个坐标已知的物体,知道在标准空间的坐标,知道像素坐标,就能根据关系求出相关的相机参数。
-
基于Homography的相机定标:有什么优点、基本的四个步骤、矩阵有几个自由度,求解需要至少几个特征点。
- 优点:灵活,鲁棒性好,成本低。仅要求相机观察在几个(至少2个)不同方向上显示的平面图案。
- 给定标定物体的N个角点,K个视角(棋盘格子两个点可以得出四个等式),求解所有的参数。N个点K个视角可以列出2NK个等式,会带来6*K+4个参数。每次会变的是外参,而内参和畸变参数是不变的,所以只需要2NK>6*K+4即可
- 矩阵自由度:8. 一个视角最多只能校准8个参数(所以需要更多的视角)。所以求解至少需要4个特征点
- 标定目标:右侧两个平面与棋盘角
- 获取标定物体网格的角点在坐标系的位置
- 找到图片的角点
- 根据图像空间坐标系到世界坐标系列出等式,求解相机参数
即:拍照 - 找特征点 - 特征点对应 - 计算公式和参数


立体视觉
两张同时拍摄的位置不同的图片,两个相机拍的。构建深度图。
-
三角测量基本原理:
-
假设有两个焦距相同的完美相机,假设我们知道3维空间点在2维图像上的具体位置-相似三角形
-
disparity的这张图:
公式推导:视差,,表示左右两摄像头成像的距离;Z的结果误差主要在分母(视差)那里。视差小的时候,视差的误差会对Z产生很大的影响。此外T越小,误差越小。T越大,看到的范围越小(因为是取两图像的交叉部分)
-
-
立体视觉的基本步骤:How to do stereo
- 恢复失真,消除畸变
- 矫正相机,使图像在同一个平面上
- 在两张图中找到对应的相同特征
- 三角测量


结构光三维成像原理
- 成像系统的构成
- 一个结构光三维成像系统主要由三个部分组成:结构光投影仪(一台或多台),CCD相机(一台或多台),以及深度信息重建系统
- 利用结构光获取三维数据的基本原理,会画图,会推导公式(相似三角形)
-
- ICP算法:iterative closest point,要解决什么问题?基本步骤?
- 迭代最近点方法(用于多个摄像机的配准问题,即把多个扫描结果拼接在一起形成对扫描对象的完整描述)
- 给定两个三维点集X与Y,将Y配准到X:
- 计算Y中的每一个点在X中的对应最近点
- 求使上述对应点对的平均距离最小的刚体变换,获得刚体变换参数(平移参数和旋转参数)
- 对Y应用上一步求得的刚体变换(平移和旋转),更新Y
- 如果X与Y的对应点对平均距离大于阈值,回到1,否则停止计算

结构分割
基于区域间的不连续性(不同区域间)和相似性(同一区域内)
-
基于聚类:基本原理,基本步骤
-
聚类cluster:把相似的点分在一起,用一个标记代表它们
-
挑战:相似的判定,怎么算分组
-
K-means:迭代地将点重新分配给最近的聚类中心
- 随机选择K个聚类中心
- 对图像上所有点,根据其与聚类中心的距离,将其划分为距离最近对应的中心的聚类簇
- 重新计算每一簇中新的中心(一般取当前类内所有样本在每一维度上的均值)
- 重复2,3两步直至没有点被重新分配
- 退出迭代后,将每一簇中的所有点赋予簇中心的类别标记
缺点:K的选取没有明确规则,每次迭代要遍历整个样本集,开销大,基于距离划分——只适用于凸分布的数据集
-
-
基于mean shift:基本原理,和kernel密度估计的关系,和上一个相比的好处
- 基本原理:The mean shift algorithm seeks modes of the given set of points
- 步骤:
- Choose kernel and bandwidth
- For each point:
- a. Center a window on that point
- b. Compute the mean of the data in the search window
- c. Center the search window at the new mean location
- d. Repeat ( b,c ) until convergence
- Assign points that lead to nearby modes to the same cluster
- 关系:移动的过程中会大概向密度提升的方向移动
- 好处:Good general purpose segmentation, Flexible in number and shape of regions, Robust to outliers
-
基于Graph Cut:简单知道基本步骤,如何理解最小 Cut 对应最佳的分割
-
用户提供了粗略的前景区域指示,希望能自动得到一个像素级别的分割。把图片元素(即像素)分成不同的类别。
-
步骤:
- Constructing a graph for an image
- Find a min Cut of a graph: a partition of the vertices in the graph into two disjoint subsets
- Get the fore/background segmentation by mapping the partition to the image domain.
-
min cut:最小割就是将图切割为两个部分时,代价最小的割的集合。
从图像对应到G:像素点为顶点,边代表像素之间的关系(考虑分割,个人认为每个像素应该只和自己相邻的像素点有边),边的权值测量了成对(pairwise)相似度
图像背景前景各对应t,s,类似于网络流问题:
min cut代价最小意味着权值最低,说明两者之间相似性很差,所以是最佳分割。
-

Attention
-
曲线:自己用图之类的,自己去解释霍夫变换的原理
-
PCA:选取多少个特征向量构建子空间,课件有公式(特征值加起来分子分母加起来,能量比……),含义说清楚。
-
图像拼接:关键:有个计算要会算,给出outliner有多少比例,k次loop之后,成功概率是多少。课件里有一个例题,一定要会,一定要熟练掌握,很容易搞混。计算题。
-
CNN-给一个例子,能算梯度反向传播的过程,给一个具体函数,初始值,能算出来。ppt的例子还没看
-
针孔相机模型:有外参的还没仔细推导,还没背会
-
结构分割-mean shift和kernel密度估计的关系,和上一个相比的好处
-
LoG算子为什么加高斯
-
Harris角点灰度仿射不变性
-
SIFT尺度不变的原理
-
霍夫变换离散化精度高低影响
-
PCA什么样的数据比较有效?高斯分布,多维高斯,多元高斯分布。这里的含义:重构的含义,重构误差比较小
-
RANSAC算法解决什么问题
-
物体识别——基于卷积全局优化的物体分类:简单推导并理解含义。得到的两个公式,什么含义,或者给一个符号/想法,能简单的每个类别一个feature推导出来。自己能解释的写出来。
-
神经网络的学习,数学本质上是求解什么,常用的基本方法(连接的权重?)
-
CNN-会计算第一个卷积层的各种权重个数,注意权重数和连接数的差别,权重是共享的,要小很多。很容易弄错。
-
CNN-梯度下降法学习框架
-
立体视觉的基本步骤关键是什么